
Can We Trust AI? Statistics Has The Answer
- Dr Khalid W. A. Shomali

- Jun 2
- 6 min read
Artificial intelligence is quickly becoming part of daily life. AI is increasingly making decisions that impact millions of people, from financial systems to medical diagnoses. However, there is still a crucial question: Can we really rely on AI systems to act consistently in real-world situations?
Even though contemporary AI models are capable of remarkable accuracy in controlled settings, real-world situations are significantly more unpredictable. Adversarial attacks, biased models, unexpected inputs, and low-quality data can all lead to unpredictable failures in AI systems. Understanding the reasons behind these failures has emerged as one of the most significant concerns in artificial intelligence research as AI continues to advance into high-stakes applications.
This article explores AI reliability through the SMART framework proposed by Hong et al. (2023), highlighting how the environment, data, and the model itself can influence the reliability and trustworthiness of AI systems.
SMART Framework
Hong et al. (2023) proposed the SMART framework as a structured approach for studying AI reliability. The framework consists of five interconnected components. Together, these elements support a systematic understanding of AI system design, reliability measurement, failure analysis, reliability prediction, and efficient testing strategies.
The five components of the SMART framework are:
Structure of the system: Understanding the architecture and organisation of the AI system is the first step in assessing reliability.
Metrics of reliability: Appropriate reliability metrics must be defined to collect relevant data and monitor reliability over time.
Analysis of failure causes: Failure analysis helps determine how the system fails and which factors influence its reliability.
Reliability assessments: Reliability assessment involves modelling, estimating, and predicting system reliability.
Test planning: Effective testing strategies are required to ensure efficient collection of reliability data.
In reliability assessment, Hong et al. (2023) proposed a statistical framework for understanding how AI systems fail over time as well. Instead of viewing failures as isolated incidents, the framework treats them as events that occur continuously during the operation of the system.
The framework considers different types of disruptive events that may eventually lead to failures. These disruptions can come from several sources, including changes in the operating environment, problems in the data, or weaknesses in the AI model itself. Examples include distribution shifts, noisy or corrupted data, and adversarial attacks (see Figure 1).
Each disruptive event has a certain likelihood of causing an actual system failure. This likelihood depends not only on external conditions, but also on the internal reliability of the AI system. For instance, AI models that are better at detecting unfamiliar or out-of-distribution data are generally more resistant to failures caused by unexpected inputs.
Overall, the framework suggests that AI systems with stronger internal reliability are less affected by disruptive events and are therefore more dependable. However, the study also highlights the need for more advanced statistical models and better testing data to improve AI reliability research.

A Closer Look at the Possible Causes of AI Failure
Enivornment
One of the major factors affecting AI reliability is the operating environment. AI systems are usually trained under specific environmental conditions and data distributions. When the operating environment changes, the model may encounter unfamiliar inputs that differ from what it learned during training. These unfamiliar inputs are commonly referred to as out-of-distribution (OOD) data. Imagine teaching someone to identify fruits using only apples, bananas, and oranges. Later, they come across a dragon fruit or a kiwi for the first time. Naturally, they would struggle to recognize it. Deep neural networks face a similar limitation, known as the closed-world assumption. At the core of many neural networks lies the assumption that the system will only encounter data similar to what it was trained on. In other words, the model expects the world to remain familiar. However, the real challenge is not simply recognizing known patterns — it is handling unfamiliar and unexpected inputs. The key issue lies in the test data distribution.
For machine learning models to perform effectively, the test data should ideally follow the same distribution as the training data. In practice, though, real-world data often differs from what the model has previously seen. This mismatch can significantly reduce performance and reliability, highlighting the importance of detecting out-of-distribution (OOD) data.
Another element of the operating environment system is the distribution shift. It refers to any situation in which the data used during training differs from the data encountered during testing. This is a major challenge in machine learning because most models are built on the assumption that both training and test data follow the same underlying distribution.
Most machine learning algorithms rely on the foundational statistical assumption that data points are independent and identically distributed (i.i.d.) (meaning one sample does not affect another and all samples originate from the same probability distribution). When this assumption no longer holds due to a distribution shift, model performance can decline substantially. Moreover, different forms of distribution shift often require different strategies to maintain model reliability and performance. One type of Distribution Shift is the Covariate Shift. In this case, the characteristics of the input data differ, but the underlying (conditional) relationship stays stable. For example, a speech recognition system trained primarily on adult voices is later deployed to recognize children’s voices.
Data
Since machine learning models learn patterns directly from data, the quality, balance, and integrity of the data strongly affect how reliable the system will be in real-world environments. Poor or problematic data can lead to incorrect predictions, unstable behaviour, and increased system failures.
Machine Learning also has a vulnerable side that can compromise the integrity of an entire system. Adversarial attacks take advantage of weaknesses in how algorithms are designed and trained, potentially resulting in anything from stolen data to severe degradation in model performance. Adversarial attacks have become an increasing threat to AI and machine learning systems. Adversarial attacks are crafted to mislead machine learning models by introducing carefully manipulated inputs that cause incorrect predictions. These deceptive inputs are known as adversarial examples, as they are specifically designed to confuse or trick classifiers.
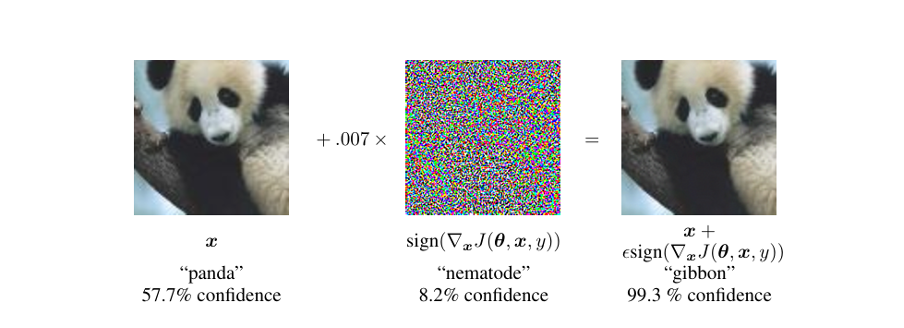
In Figure (2), Goodfellow et al. (2014) added a very small “noise” (7 per thousand of the pixels) to the image of a panda. But the outcome was unexpected. The classifier not only identified the panda as a gibbon, but it did so with a high degree of confidence (99.3%).
Another common issue is data imbalance. It is a widespread and important issue in machine learning that occurs when the classes within a dataset are unevenly represented. In such cases, one class contains significantly more samples than the other class or classes, leading to a skewed class distribution.
Model
The model itself is another major factor affecting AI reliability. The architecture, learning capability, and decision-making behaviour of a machine learning model determine how effectively it can interpret data and respond to different situations. Weaknesses within the model can lead to unreliable predictions, poor generalization, and system failures.
Accuracy is one of the most commonly used evaluation metrics in machine learning because it is easy to interpret — it simply measures the proportion of correct predictions out of all predictions made by the model. While this simplicity makes accuracy attractive, it can also be highly misleading in many real-world applications. Consider a medical screening system designed to detect a rare disease. If only 2% of patients actually have the disease, a model that predicts every patient as “healthy” would still achieve 98% accuracy. Although the accuracy appears very high, the model is practically useless because it fails to identify the patients who truly need medical attention.
A fundamental concept in machine learning and data science is Model bias. It remains one of the most difficult challenges for both AI developers and organizations that rely on machine learning technologies. Detecting and evaluating bias before deploying a model into production is essential. A model achieving extremely high accuracy on a specific dataset does not necessarily mean that it is reliable, robust, or truly learning meaningful patterns. Bias in machine learning refers to systematic errors caused by incorrect assumptions within an algorithm. As a result, the model may learn misleading patterns and fail to capture the true relationship between inputs and outputs. This issue arises when the algorithm lacks the ability to properly learn from the data. Although model bias has long been recognized as a major concern, it remains a difficult challenge in developing and deploying reliable machine learning systems.
Concluding Remark
Although AI systems are frequently praised for their performance and intellect, one of their biggest problems is still reliability. A model's ability to operate safely and consistently in real-world situations cannot be ensured by high accuracy alone. Distribution shifts, out-of-distribution data, adversarial attacks, data imbalance, and model bias are a few examples of factors that might impair system performance and cause unanticipated failures.
References
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. Advances in neural information processing systems, 27.
Hong, Y., Lian, J., Xu, L., Min, J., Wang, Y., Freeman, L. J., & Deng, X. (2023). Statistical perspectives on reliability of artificial intelligence systems. Quality Engineering, 35(1), 56-78.


